欢迎 使用 sybn util 项目 以下是最近更新内容 最后更新时间: 2026-07-10 10:00:05
-
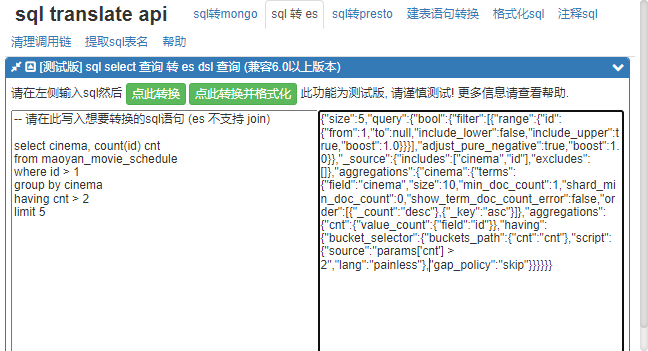
翻译 sql 语句为 es DSL
-
execBatch 批量操作
某些场景下, 需要批量执行某些 sql, 其中 sql 中表名或者字段名是变量。
原生sql中, 一般使用存储过程实现。 本工具为了满足此场景, 引入了 execBatch 批量操作。
说明
- SQL
-- 前置sql, 列出所有表名 show tables; -- 单线程批量操作, 获取所有表的表结构 execBatch(show create table @tables); ```sql -- 前置sql, 列出所有表名 show tables; -- 多线程批量操作, 获取所有表的表结构, 如果单个任务失败不影响其他任务继续执行 execBatch(show create table @tables) ON concurrent=5 and ignore_error=true;
-
CommentSql工具说明
对于复杂的 sql, 我们不清楚其表结构和索引结果. 使用 CommentSql 工具, 可以帮助我们快速阅读 sql 逻辑.
以 java 格式调用
import cn.sybn.util.io.driver.util.CommentSqlUtil; @Test public void commentSqlSimpleTest() { String sql = "-- sql\n" + "select a \n" + "from t \n" + "where b >1 and c = 1 and d is not null;\n" + "-- 建表语句\n" + "create table `t` (\n" + " a int comment '字段a注释',\n" + " b int comment '字段b注释',\n" + " c int comment '字段c注释',\n" + " d int comment '字段c注释',\n" + " PRIMARY KEY (`a`),\n" + " UNIQUE KEY `b` (`b`),\n" + " KEY `b_c` (`b`,`c`)\n" + ")\n"; String s = CommentSqlUtil.commentSql(sql); }
-
todo list
-
fill 数据补全
在 echart 等业务场景下, 查询N天的数据时, 希望返回一天一行, 一共N行数据.
但是从数据库 group by 出来的数据可能不够7行, 需要将没有数据的日期填充进来.
说明
处理前的数据
select date, sum(v) as v from [{date:'2021-12-03',v:3},{date:'2021-12-06',v:6}] group by datedate v 2021-12-03 3 2021-12-06 3
-
from factory 数据行填充
在 echart 等业务场景下, 查询N天的数据时, 希望返回横坐标一天一行的, 一共N行数据.
但是从数据库 group by 出来的数据可能因部分日期数据缺失不够7行, 此时需要将没有数据的日期填充进来.
说明
处理前的数据
select date, sum(v) as v from [{date:'2021-12-03',v:3},{date:'2021-12-06',v:6}] group by datedate v 2021-12-03 3 2021-12-06 3
加微信请备注sybn

入门内容
最近更新的文档
文档分类
Tags
手机打开本页面