欢迎 使用 sybn util 项目 以下是最近更新内容 最后更新时间: 2026-07-10 10:00:05
-
LogUtil 日志工具
LogUtil 是底层实用日志工具, 可以代理 self4j 打印日志.
-
show value stat 分析表数据
SHOW VALUE STAT 可在数据库中统计数据概况, 比如统计最大值最小值和null值的数量. 不计算词频, 如需统计词频可使用 AnalyticalTable 工具.
可以对 jdbc(mysql, presto, gbase, hive, clickhouse) / solr / es / mongo / hbase / execl / csv / json 等与数据执行字段分析.
-
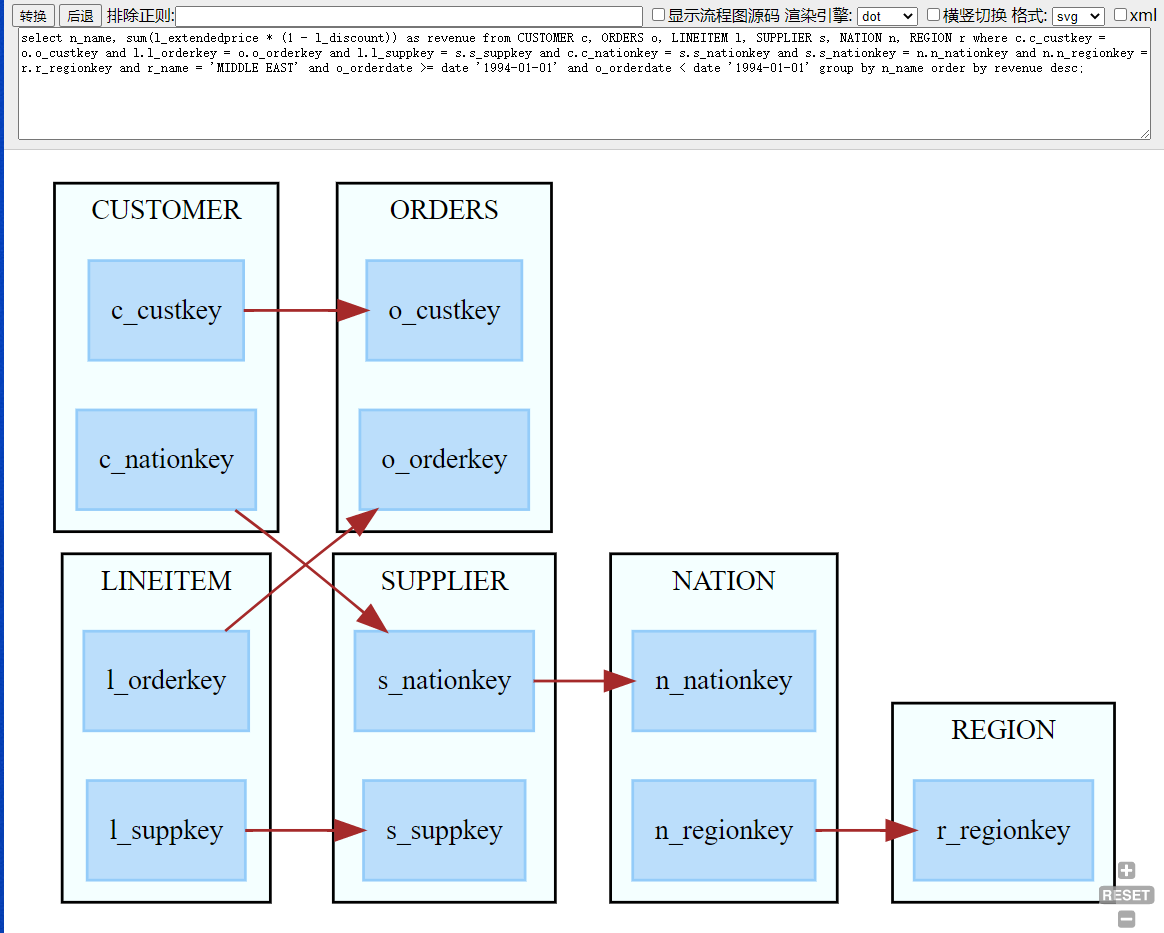
AnalyticalSqlJoin 分析并可视化表关系
-
dynamicSourceQuery 向临时数据源发起链接
某些场景下,需要临时连接到,未提前定义的或者随时变更的数据库。
在 mysql 中可以创建远程表 (federated engine) 来实现.
本工具提供了类似的实现方案, 无需建虚拟表可直接链接临时数据源.
语法
- SQL
dynamicSourceQuery(select * from xxx) on url='jdbc:sqlite:/usr/local/junit/data/sqlite_3.db'
-
对if语句的支持
本工具包支持接近sql风格的 if 语句, 实际对于 if 语句的支持如下:
-- 判断子查询是否有值 if [not] exists (select code from xxx) [then (select 1)] [else (select 2)] [end if] -- 判断表达式 if [not] (@a>1) select 1 -- 判断表是否存在 if [not] exists table (table1, table2, ...) [then (select 1)] [else (select 2)] [end if] -- 判断字段是否存在 if [not] exists [table] field (table1.field1, table2[.field2], ...) [then (select 1)] [else (select 2)] [end if]
-
批量加载mysql数据到es
某些场景下, 需要批量载入数据到其他数据源.
以 es 为例, 相关代码如下:
说明
批量复制数据
// 初始化各种数据源, 为了容易理解这里使用直接传入jdbc的实现类 SybnStreamDao dao1 = new DbutilStreamDaoImpl("jdbc:mysql://账户:密码@192.168.4.31:3306,192.168.4.32:3306/test"); // sql // SybnStreamDao dao2 = new MongoStreamDaoImpl("mongodb://账户:密码@192.168.4.31:27017,192.168.4.32:27017/test"); // mongo // SybnStreamDao dao3 = new SolrStreamDaoImpl("solr://192.168.7.71:2181,192.168.7.72:2181/solr"); // solr EsStreamDaoImpl dao4 = new EsStreamDaoImpl("es", "es://192.168.7.71:9200,192.168.7.72:9200"); // es // SybnStreamDao dao5 = new HBaseStreamDaoImpl("hbase://192.168.7.71,192.168.7.72/hbase-unsecure"); // HBase // 设置 es 的数据落盘时间, 防止频繁落盘降低性能. dao4.setEsRefreshInterval("xxx_es", 300); // 设置每次个批次写入的数据量 dao4.setSaveBatchSize(3000); // 流式读取数据 Stream<Map<String, Object>> mapStream = dao1.sqlFindStreamMap("select * from xxx where id > 123"); // 流式写入数据 dao4.commonSaveStream("xxx_es", mapStream); // 恢复设置 es 的数据落盘时间为1秒. dao4.setEsRefreshInterval("xxx_es", 1);- 语法
实测效率再 5000行/秒 左右, 此数据受 单行数据大小, 磁盘io 和 网络速度 等因素影响.
加微信请备注sybn

入门内容
最近更新的文档
文档分类
Tags
手机打开本页面