欢迎 使用 sybn util 项目 以下是最近更新内容 最后更新时间: 2026-07-10 10:00:05
-
data view 数据视图
简介
使用sql语句查询到的数据是二维数据,本身可以映射为一个 excel 或者 table, 但是无法直接准换为 echarts 图表.
为了解决数据可视化问题, 我们准备了 data view 工具, 将 sql 的结果数据直接转换为 echarts 可用的数据, 或者其他需要的数据格式.
开发流程
- 先开发 ResultConver 实现类,负责转换结果集. 比如下面的 to_scope_list 方法的实现类是 ResultToCharMapJsonConver .
- 将 ResultConver 注册到 ResultToMapConverPool 中.
- Controller 接口调用 ResultConver.conver() 方法,实现根据前端传参返回指定格式的数据.
to_scope_list 使用样例
- to_scope_list 视图
import cn.sybn.bean.result.conver.result.ResultToMapConverPool; import cn.sybn.bean.result.conver.result.ResultConver; /* to_scope_list(timeField, timeScope, timeConver, aggFields, groupKeys, interval, defaults); - timeField x轴对应的字段 - timeScope x轴为盈的范围(比如: 180101~180201, 1~10) - timeConver x轴转换类(比如: to_date(), to_long() 经常遇到x轴的值为String,但需要int型的x轴,此参数可以对此做数据转换 - aggFields 折线的field, 用于控制一行 row 中有几条折线 - groupKeys 折线的key - interval 非必须,x轴的间隔, (比如: 86400, 1, 1DAY, 1MONTH 等) - defaults 非必须,折线图无值时,数据当什么处理,一般为 null 或者 0 */ String resultView = "to_scope_list(t, '20190101~20190131', to_date(), 't', 'c', '1DAY', 0)" List<Map<String, Object>> data = dao.sqlFindListMap("select t, count(*) as c from table where t between 20180101 and 20180131 group by t order by t") ResultBase res = new ResultTRows<>(data); ResultConver resultConver = ResultToMapConverPool.get(resultView); ResultBase res2 = resultConver.conver(res);- 返回值
{ "result" : true, "msg" : "success", "total" : 1, "attachment" : { "_group_by" : [ ], "_group_fields" : [ "c" ], "_group_x_field" : "t", "_group_y_field" : "'c'", "_group_scope_interval" : "1DAY", "_group_scope_list" : [ "2019-01-01", "2019-01-02", "2019-01-03", "2019-01-04", "2019-01-05", "2019-01-06", "2019-01-07", "2019-01-08", "2019-01-09", "2019-01-10", "2019-01-11", "2019-01-12", "2019-01-13", "2019-01-14", "2019-01-15", "2019-01-16", "2019-01-17", "2019-01-18", "2019-01-19", "2019-01-20", "2019-01-21", "2019-01-22", "2019-01-23", "2019-01-24", "2019-01-25", "2019-01-26", "2019-01-27", "2019-01-28" ] }, "rows" : [ { "_" : null, "value_scope_start" : "2019-01-01", "value_scope_end" : "2019-01-28", "plan" : [ 98832, 89188, 88477, 94331, 98127, 97541, 88971, 91883, 90769, 89554, 101539, 101411, 100595, 91890, 91782, 92129, 91568, 102538, 103876, 103814, 95736, 95367, 95750, 96365, 99826, 102768, 102364, 95084 ], "ticket" : [ 7454, 2097, 1735, 5957, 7649, 6009, 2353, 2063, 2079, 2012, 3611, 5106, 4042, 2010, 1882, 2137, 2105, 3713, 5120, 4895, 2455, 2133, 2428, 2114, 4300, 4458, 4071, 2494 ], "sum_plan" : 2692075.0, "sum_ticket" : 98482.0 } ] }- 前端渲染
前端使用 charts.js 直接将上面的json结果集渲染为折线图.
如果有美化要求,可以让前端人员修改.
- 集成工具
上述内容已经集成进 api-core 接口项目中,
api-core 是业务层通用组件, 本文档主要讲述 dao 层通用组件,因此不专门阐述.
以下是 api-core 效果图, 集成了 跨库dao,sql代码提示, 数据可视化三个特性.
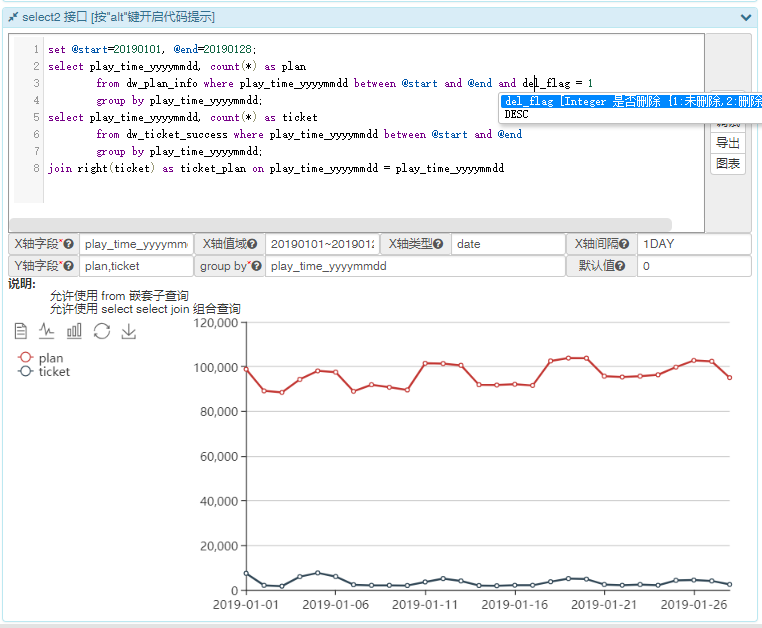
-
公共数据CRUD操作
简介
本工具类提供多数据源一致的数据 CRUD 能力, 并支持使用 sql 查询所有数据源, 主要功能如下.
- commonSave 提供 jdbc(mysql, presto, clickhouse), mongo, solr, elastic search, hbase 保存数据统一接口
- commonUpdate 提供 jdbc(mysql, presto, clickhouse), mongo, solr, elastic search, hbase 修改数据统一接口
- commonRemove 提供 jdbc(mysql, presto, clickhouse), mongo, solr, elastic search, hbase 删除数据统一接口
- sqlFindList 提供 jdbc(mysql, presto, clickhouse), mongo, solr, elastic search, hbase, redis 查询 List 统一接口
- sqlFindStream 提供 jdbc(mysql, presto, clickhouse), mongo, solr, elastic search, hbase, redis 查询 Steam 数据流统一接口
相关页面
-
sybn dao 使用子查询与union
简介
标准的 sql 语句中查询嵌套查询和很常见的,但是 sybn dao 默认都只支持单表查询。
为了解决查询嵌套的问题, 准备了专门的 dao 实现: SqlDdlDaoMultipleImpl
-- 本层查询由 java 执行 select name, sum(c) as c from ( -- 启动时会通过 show tables 注册每个数据库有那些表 -- 本层查询路由到 mysql, 依据来自 from 和 join 的表名 select name, count(*) as c from sql_demo_table group by name -- union 操作由 java 执行 union all -- 本层查询路由到 elastic search, 如果表重名则加数据库名即可 select name, count(*) as c from es.demo_table group by name union all -- 本层查询路由到 mongo, sql 会被转为 aggergate 表达式, mongo 1 != "1" select name, count(*) as c from mongo.demo_table group by name union all -- 本层查询路由到 presto, sql 会被转为 presto 方言格式, 支持 ${hiveconfig:x} select `name`, count(*) as c from presto_demo_table group by name union all -- 本层查询路由到 hbase, 注意 group by 部分由 java 实现, 所有比较操作为字符串比较 select name, count(*) as c from hbase_demo_table group by name ) group by name在线测试
可以用以下链接尝测试执行sql, 其中的 sql 及 json数据 可以随意替换. 也可以使用测试表: sql_demo_table,mongo_demo_table,cinema_info
使用样例
- 准备 SqlDdlDaoMultipleImpl
// 初始化各种数据源, 为了容易理解这里使用直接传入jdbc的实现类 SqlDdlDao dao1 = new DbutilDaoImpl("jdbc:mysql://账户:密码@192.168.4.31:3306,192.168.4.32:3306/test"); // sql SqlDdlDao dao2 = new MongoDaoImpl("mongodb://账户:密码@192.168.4.31:27017,192.168.4.32:27017/test"); // mongo SqlDdlDao dao3 = new SolrDaoImpl("solr://192.168.7.71:2181,192.168.7.72:2181/solr"); // solr SqlDdlDao dao4 = new EsDaoImpl("es://192.168.7.71:9200,192.168.7.72:9200"); // es SqlDdlDao dao5 = new HBaseDaoImpl("hbase://192.168.7.71,192.168.7.72/hbase-unsecure"); // HBase // 推荐使用配置文件管理数据库连接信息, 比如: SqlDdlDao dao1 = new DbutilDaoConfImpl("mysql_test@xxx.properties") // 构造 SqlDdlDaoMultipleImpl, 并将以上数据源注册进来. SqlDdlDaoMultipleImpl multipleDao = new SqlDdlDaoMultipleImpl(); multipleDao.addAllTableSource(dao1); multipleDao.addAllTableSource(dao2); multipleDao.addAllTableSource(dao3); multipleDao.addAllTableSource(dao4); multipleDao.addAllTableSource(dao5);- from 子查询
String sql = " select type_name,sum(count) as count from ( select type,count(*) as count from table1 group by type; select type,type_name from table2; join right(type_name) on left.type = right.type; ) group by type_name"; List<Map<String,Object>> mapList = multipleDao.sqlFindListMap(sql); List<Bean> beanList = multipleDao.sqlFindList(sql, Bean.class);- select 子查询 V:0.2.19
String sql = " select * from table1 where id in ( select id from table2 );" List<Map<String,Object>> mapList = multipleDao.sqlFindListMap(sql); List<Bean> beanList = multipleDao.sqlFindList(sql, Bean.class);- union V:0.2.18
String sql = " select * from table1 union all select * from table2;" List<Map<String,Object>> mapList = multipleDao.sqlFindListMap(sql); List<Bean> beanList = multipleDao.sqlFindList(sql, Bean.class);- 临时变量 V:0.3.4
-- 支持 mysql风格的临时变量 set @time_date_str := '2019-01-16', @time := str_to_date(@time_date_str, '%Y-%m-%d'); select * from table where time_str > @time_date_str and time > @time -- 扩展支持 list 型变量 set @a@list = (1028, 1029, 1030, 1031, 1032); select * from table where id in (@a@list); -- 扩展支持 list 型变量,并内嵌函数和变量 set @a = 1032; set @a@list = (1028, CONVERT("1029", SIGNED), CAST("1030" as SIGNED), toInt("1031"), @a); select * from table where id in (@a@list); -- 扩展支持 list 型变量,并从查询获取值 set @a@list = (SELECT id FROM table order by id limit 5); select * from table where id in (@a@list);不支持功能
因为 join 的功能还没写完所以暂时使用 select + select + join 的方式实现 join 操作。
-- ## 第一次 join -- table1 的 sql 的返回值会被压入堆栈,坐标[0] select type,count(*) as count from table1 group by type; -- table2 的 sql 的返回值会被压入堆栈,坐标[1] select type,type_name from table2; -- join 会按先进后出的原则从堆栈的结尾获取表, 先取出[1]定义为 right, 再取出[0]定义为 left -- join 会将 right 的 type_name 写入 left,然后从堆栈删除 right [1], 此时堆栈只剩下[0] join right(type_name) on left.type = right.type; -- ## 再次 join (按顺利连续join) -- table3 的 sql 的返回值会被压入堆栈,坐标[1] select type_name_creatime,type_name from table3; -- # 第二次的 join 会将其前方此sql的返回值认定为 right 表, 而其前方第二张表也就是 第一次精品 -- join 会按先进后出的原则从堆栈的结尾获取表, 先取出[1]定义为 right, 再取出[0]定义为 left -- join 会将 right 的 type_name_creatime 写入 left,然后从堆栈删除 right [1], 此时堆栈只剩下[0] join right(type_name_creatime) on left.type_name = right.type_name; -- # join 会将 right 表指定字段查询 left 表,然后返回 left 表 -- ## 嵌套 join 右表本身有 join 逻辑 -- table1 的 sql 的返回值会被压入堆栈,坐标[1] select type,type_id from table4; -- table2 的 sql 的返回值会被压入堆栈,坐标[2] select type_id, type_id_createtime from table4; -- join 会按先进后出的原则从堆栈的结尾获取表, 先取出[2]定义为 right, 再取出[1]定义为 left -- join 会将 right 的 type_name 写入 left,然后从堆栈删除 right [2], 此时堆栈只剩下[0]和[1] join right(type_id_createtime) on left.type = right.type;注意事项
- 关于返回值列顺序
SqlDdlDaoMultipleImpl 返回 map 时,只保证第一条数据的返回字段顺序与 select 语句一致, 比如:
select a,b,c from mongo_table -- 返回值可能如下形式: -- [{a:1,b:2,c:3}, // 第一条,字段顺序与sql一致 -- {b:2,a:1,c:3}, ...] // 第二条及之后内容,字段顺序可能是hash顺序考虑到列排序对于性能的影响,某些情况下(比如数据量较少时)可能会对所有数据排序,但返回值行数较多时只保证第一行的顺序。
如果须要严格将所有数据的每一列顺序对齐,可以要求返回 java bean,或者使用以下工具类排序:
MapsUtil.orderMaps(List<Map<String, V>> source, List<String> keys); MapsUtil.orderMaps(Stream<Map<String, V>> source, List<String> keys);相关页面
-
解决无法读取 jar 包中的 excel 文件
-
DateScope 时间枚举工具
简介
部分业务需要枚举一个时间范围内的 每N天 或 每N个月, 所以准备了 DateScope 和 DateMonthScope.
DateScope 示例代码
- 按天枚举
import cn.sybn.bean.scope.DateScope; // 闭区间, 支持日常常用的多种时间格式 DateScope scope = DateScope.create("20180101~2018-01-05"); // 默认打印每一天 int size = scope.size(); // size = 5 StringBuilder sb = new StringBuilder(); for (Date date : scope) { sb.append(DayUtil.dayToInt(date)); sb.append("/"); } sb.toString(); // sb = "20180101/20180102/20180103/20180104/20180105/" // 枚举String格式的时间 sb = new StringBuilder(); for (String dateStr : scope.dateformatIterator("yyyyMMdd")){ sb.append(dateStr); sb.append("/"); } sb.toString(); // sb = "20180101/20180102/20180103/20180104/20180105/" // 打印每2天 scope.setStep(2 * 86400000L); // 单位 毫秒 size = scope.size(); // size = 3 sb = new StringBuilder(); for (Date date : scope) { sb.append(DayUtil.dayToInt(date)); sb.append("/"); } sb.toString(); // sb = "20180101/20180103/20180105/"DateMonthScope 示例代码
- 按月枚举
import cn.sybn.bean.scope.DateMonthScope; // 闭区间, 支持多种时间格式, 只使用年月, 忽略天和时分秒 DateMonthScope scope = DateMonthScope.create("20180101~2018-12-05"); // 打印每月 int size = scope.size(); // size = 12 StringBuilder sb = new StringBuilder(); for (Date date : scope) { sb.append(DayUtil.dayToInt(date)); sb.append("/"); } sb.toString(); // sb = "20180101/20180201/" // 打印每2天 scope.setStep(2); // 单位 月 size = scope.size(); // size = 6 sb = new StringBuilder(); for (Date date : scope) { sb.append(DayUtil.dayToInt(date)); sb.append("/"); } sb.toString(); // sb = "20180101/20180103/20180105/"类似的工具类
- IntegerScope
整数枚举, 用法与DateScope相同
- NumberScope
数字枚举, 用法与DateScope相同
-
sybn join dao 开发计划
简介
当前版本的 SqlDdlDao 的所有实现类都只支持单表查询, 需要使用 join 功能时,需要额外调用 DatasLeftJoinUtil 才能实现.
这将造成查询代码和join代码的分离, 无法实现 sql 重的 join 语句.
因此, 需要写一个新的 SqlDdlDao 实现类, 将 DatasLeftJoinUtil 中的 join 功能加入进去.
目标代码
- 旧版本的实现方式, 需要分成三行sql代码来处理.
// 可以在静态类里存放每一个dao SqlDdlDao leftDao = new HbaseDaoImpl("leftDao", "hbase://server_1:2121,server_2:2121/"); SqlDdlDao rightDao = new MongoDaoImpl("rightDao", "mongo://username:password@127.0.0.1:27017"); // left 有三个字段: id,a,b List<Map<String, Object>> left = leftDao.sqlFindListMap("select id, a, b from left where a > 0"); // right 有三个字段: id,left_id,c List<Map<String, Object>> right = rightDao.sqlFindListMap("select id, left_id, c from right where c > 0"); // join 后 left 有五个字段: id,a,b,right_id,c DatasLeftJoinUtil.join(left, right, "join right(id as right_id, c) on left.id = right.left_id");- 需要开发新版本的实现方式, 只要一行sql代码.
// 现在只需要一个大的dao, 并将各个小的dao注册进来 Map<String, SqlDdlDao> allSource = new HashMap<>(); allSource.put("left", leftDao); // 注册 left 表使用 leftDao 来操作 allSource.put("right", rightDao); // 注册 right 表使用 rightDao 来操作 SqlDdlDao allSourceDao = new SqlDdlDaoAutoSourceImpl(allSource) // 以下代码等效于之前的三行代码 String sql = "select left.id, left.a, left.b, rigth.id as right_id, right.c from left as left" + " join (select id, left_id, c from right) as right on left.id = right.left_id"; List<Map<String, Object>> left = allSourceDao.sqlFindListMap(sql);- 新版本的业务逻辑
// 1. 入参 String sql = "select left.id, left.a, left.b, rigth.id as right_id, right.c from left as left" + " join (select id, left_id, c from right where c > 0) as right on left.id = right.left_id" + " where left.a > 0" // 2. 拆分 String leftSql = "select id, a, b from left where a > 0"; String rightSql = "select id, left_id, c from right where c > 0"; String joinSql = "join right(id as right_id, c) on left.id = right.left_id"; String postSql = ""; // 某些情况下会对 join 后的结果执行二次过滤 // 3. 调用不同的dao执行sql, 可能有二次嵌套- 已实现的业务逻辑
SqlDdlDaoMultipleImpl dao = new SqlDdlDaoMultipleImpl(); List<Map<String, Object>> targetDatas = JsonTools.parseJsonToListMap("[{a:1,b:2},{a:11,b:22},{a:111,b:222}]"); List<Map<String, Object>> sourceDatas = JsonTools.parseJsonToListMap("[{c:1,d:3},{c:11,d:33},{c:111,d:333}]"); dao.addTableSource("table1", targetDatas); dao.addTableSource("table2", sourceDatas); String sysql = "select * from table1;select * from table2;join right(d) on a = c"; List<Map<String, Object>> maps = dao.sqlFindListMap(sysql); // maps = [{"a":1,"b":2,"d":3},{"a":11,"b":22,"d":33},{"a":111,"b":222,"d":333}]不支持功能
因为本工具包不要求注册数据结构,因此无法自动推断字段属于哪张表,所有的字段必须只用前缀标记所属表名.
注意事项
- 暂无
相关页面
