欢迎 使用 sybn util 项目 以下是最近更新内容 最后更新时间: 2026-07-10 10:00:05
-
FillListUtil 数据对齐工具
-
HBaseDao 介绍
简介
HBaseDaoImpl 是 SqlDdlDao 接口的 hbase 实现类, 实现了基于sql的各种数据查询能力.
- 支持连接 原生 hbase 集群
- 支持连接 阿里云的 hbase serverless. (0.3.11版)
- 支持注入到 SqlDdlDaoMultipleImpl 做跨存储引擎的数据查询.
- 支持通过 sybn-jdbc-driver 查询 hbase 数据.
- 无需依赖 phoenix, 本工具与 phoenix 一样都可直接操作 hbase.
-
dw-util-select-file.jar 介绍
简介
为了方便查询离线文件, 准备了 dw-util-select-file.jar.
支持查询本地多个 csv, json, xls, xlsx 文件中的数据,支持联合查询
使用说明
语法: java -jar dw-util-select-xls.jar [--out=输出路径] 'sql' '数据文件路径1' ['数据文件路径2' ...] sql 此伪sql支持多表嵌套嵌套查询,少部分语法与mysql不一致 文件路径 可以为多个 csv, json, xls, xlsx 文件, 第一个xls会映射为'data_1'表,第二个为'data_2'...所有xls的数据会映射为'data_all'表- 举例A: 一次查询多个 excel 的集合
java -jar dw-util-select-xls.jar "select type, max(num) as max_num, min(num) as min_num from data_all where type != 'A' group by type order by type" 'd:/num_1.xlsx' 'd:/num2.xlsx'- 举例B: 嵌套查询多个 excel
java -jar dw-util-select-xls.jar "select type, max(num) as max_num, min(num) as min_num from data_1 where type not in (select type from data_2 where id = 2) group by type order by type" 'd:/num_1.xlsx' 'd:/type.xls'下载地址:
- 20190628版 点此下载jar 约23MB
相关页面
-
to_scope_list 数据可以化视图 (附在线测试)
简介
使用sql查询到的数据,可以输出为一个 excel 或者 table。因为sql中无法表达 x轴 y轴 等定义信息, 无法直接输出为 echarts 图表。
为了解决数据可视化问题, 我们准备了 data view 工具。将 sql 的结果直接输出为 echarts 可用的格式, 或者其他需要的数据格式。
to_scope_list 函数是折线图与柱图的 data view 实现。
使用说明
to_scope_list('t', '20200101~20200131', 'date', 't', 'c', '1DAY', 0)- to_scope_list 参数说明 v:0.3.2
参数 限制 举例 说明 xField 必填,唯一 x x轴对应的字段 xScope 可选 date范围:180101~180201
long范围:1~10
str指定范围:北京,上海,广州
str自适应:null
指定策略, 比如按指定字段降序排列:
order by sum(value) desc limit 10 (limit N 与 desc 非必填)x轴的范围 xConver 可选 日期用:date 或 to_date()
数字用:long 或, to_long()
字符串用:string不区分大小写, x轴转换类
经常遇到x轴的值为String, 但需要int型递增
此参数可以对此做数据转换aggFields 必填,不唯一 plan 折线的field, 用于控制一行 row 中有几条折线 groupKeys 必填,不唯一 x, x1, x2 折线的key, 用于生成图例 interval 可选 86400, 1, 1DAY, 1MONTH x轴的间隔, defaults 可选 null 或者 0 折线图无值时,数据当什么处理. to_scope_list 使用样例
- to_scope_list 视图
import cn.sybn.bean.result.conver.result.ResultToMapConverPool; String resultView = "to_scope_list('t', '20190101~20190131', 'to_date()', 't', 'c', '1DAY', 0)" List<Map<String, Object>> data = dao.sqlFindListMap("select t, count(*) as c from table where t between 20180101 and 20180131 group by t order by t") ResultBase res = new ResultTRows<>(data); ResultConver resultConver = ResultToMapConverPool.get(resultView); ResultBase res2 = resultConver.conver(res);- 返回值
{ "result" : true, "msg" : "success", "total" : 1, "attachment" : { "_group_by" : [ ], "_group_fields" : [ "c" ], "_group_x_field" : "t", "_group_y_field" : "'c'", "_group_scope_interval" : "1DAY", "_group_scope_list" : [ "2019-01-01", "2019-01-02", "2019-01-03", "2019-01-04", "2019-01-05", "2019-01-06", "2019-01-07", "2019-01-08", "2019-01-09", "2019-01-10", "2019-01-11", "2019-01-12", "2019-01-13", "2019-01-14", "2019-01-15", "2019-01-16", "2019-01-17", "2019-01-18", "2019-01-19", "2019-01-20", "2019-01-21", "2019-01-22", "2019-01-23", "2019-01-24", "2019-01-25", "2019-01-26", "2019-01-27", "2019-01-28" ] }, "rows" : [ { "_" : null, "value_scope_start" : "2019-01-01", "value_scope_end" : "2019-01-28", "plan" : [ 98832, 89188, 88477, 94331, 98127, 97541, 88971, 91883, 90769, 89554, 101539, 101411, 100595, 91890, 91782, 92129, 91568, 102538, 103876, 103814, 95736, 95367, 95750, 96365, 99826, 102768, 102364, 95084 ], "ticket" : [ 7454, 2097, 1735, 5957, 7649, 6009, 2353, 2063, 2079, 2012, 3611, 5106, 4042, 2010, 1882, 2137, 2105, 3713, 5120, 4895, 2455, 2133, 2428, 2114, 4300, 4458, 4071, 2494 ], "sum_plan" : 2692075.0, "sum_ticket" : 98482.0 } ] }- 前端渲染
前端可以使用 charts.js 直接将上面的 json 结果集渲染为折线图.
如果有美化要求,可以让前端人员修改 charts 风格.
- 集成工具
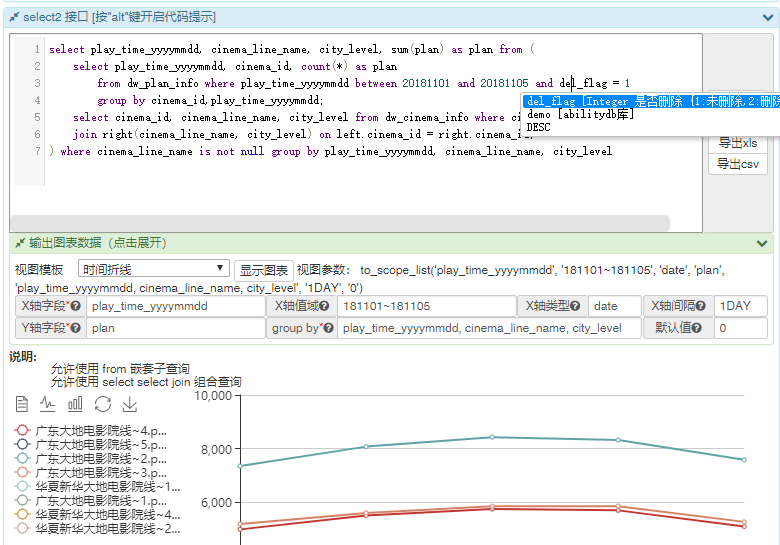
上述内容已经集成进 api-core 接口项目中,
api-core 是业务层通用组件, 本文档主要讲述 dao 层通用组件,因此不专门阐述.
以下是 api-core 效果图, 集成了跨数据库类型查询 ,sql代码提示, 数据可视化三个特性.
近期更新
-
2019-04-28 V:0.3.2
支持 string 型x轴, 并支持自适应和动态适配。
-
sql 语句转 mongo aggregate 语句的简单介绍
简介
部分同学不熟悉 mongodb 的查询语法,为了降低入门门槛,今天专门提供了转换类。
已经为大家准备好了 web 版接口: 在线测试
使用方法
// params 支持 ? 和 #{name} 占位符 MongoAggregateBuilder.makPipeline(@NonNull String sql, Object... params)举例
- 输入 SQL:
select (case type when 1 then value1 when 2 then value2 else 0 end) as t, count(*) as c from table where date > str_to_date('2019-04-07', '%Y-%m-%d') group by t having c > 10 order by c desc-
输出 Aggregate:
[ {"$match":{"date":{"$gt":{"$date":"2019-04-06T16:00:00Z"}}}}, {"$group":{"_id":{"t":{"$cond":{"if":{"$eq":["$type",1]},"then":"$value1","else":{"$cond":{"if":{"$eq":["$type",2]},"then":"$value2","else":0}}}}},"c":{"$sum":1}}}, {"$project":{"_id":0,"t":"$_id.t","c":1}}, {"$match":{"c":{"$gt": 10}}}, {"$sort":{"c":-1}} ]注意事项
-
mongo 只能支持 select 和 from 子查询, 无法支持 where 子查查询 和 join
-
此工具类暂时不支持加减乘除运算
-
mongo对数据类型敏感,MySQL 中的 date > str_to_date(‘2019-04-07’, ‘%Y-%m-%d’) 可以写为 date > ‘2019-04-07’ 但 mongo 不可以。
web 版
- 以下是web版效果图 在线测试
- 手机扫码试用

相关页面
-
sql 语句转 mongo aggregate 语句的各种例子
简介
部分同学不熟悉 mongodb 的查询语法,为了降低入门门槛,今天专门提供了转换类。
已经为大家准备好了 web 版接口: 在线测试
使用方法
import cn.sybn.data.mongo.util.MongoAggregateBuilder; // params 支持 ? 和 #{name} 占位符 MongoAggregateBuilder.makPipeline(@NonNull String sql, Object... params)例1(普通sql)
- 输入 SQL:
select (case type when 1 then value1 when 2 then value2 else 0 end) as t, count(*) as c from table where date > str_to_date('2019-04-07', '%Y-%m-%d') group by t having c > 10 order by c desc-
输出 Aggregate:
[ {"$match":{"date":{"$gt":{"$date":"2019-04-06T16:00:00Z"}}}}, {"$group":{"_id":{"t":{"$cond":{"if":{"$eq":["$type",1]},"then":"$value1","else":{"$cond":{"if":{"$eq":["$type",2]},"then":"$value2","else":0}}}}},"c":{"$sum":1}}}, {"$project":{"_id":0,"t":"$_id.t","c":1}}, {"$match":{"c":{"$gt": 10}}}, {"$sort":{"c":-1}} ]例2(带unwind的sql)
- 输入 SQL:
-- 语法1 两种写法等效 select datas, count(*) as c from table group by unwind(datas) as data-- 语法2 group by 后面的字段名需要等于 as 后面的字段名 select unwind(datas) as data, count(*) as c from table group by data-
输出 Aggregate:
[ {"$unwind":"$datas"}, {"$group":{"_id":{"data":"$datas"},"c":{"$sum":1}}}, {"$project":{"_id":0,"data":"$_id.data","c":1}} ]例3(from子查询)
- 输入 SQL:
-- 求每天的用户数和总金额 select day, count(user) as user_count, sum(price_sum) as price_sum from ( select date_format(pay_time, "%Y-%m-%d") as day, user, sum(price) as price_sum from table1 group by day, user; ) group by a-
输出 Aggregate:
[ {"$group":{"_id":{"day":{"$dateToString":{"date":"$pay_time","format":"%Y-%m-%d"}},"user":"$user"},"price_sum":{"$sum":"$price"}}}, {"$project":{"_id":0,"day":"$_id.day","user":"$_id.user","price_sum":1}}, {"$group":{"_id": {"day":"$day"},"user_count":{"$sum":{"$cond":{"if":{"$gt":["$user",null]},"then":1,"else":0}}},"price_sum":{"$sum":"$price_sum"}}}, {"$project":{"_id":0,"day":"$_id.day","user_count":1,"price_sum":1}} ]例4 (select子查询 $lookup) V0.3.5
- 输入 SQL:
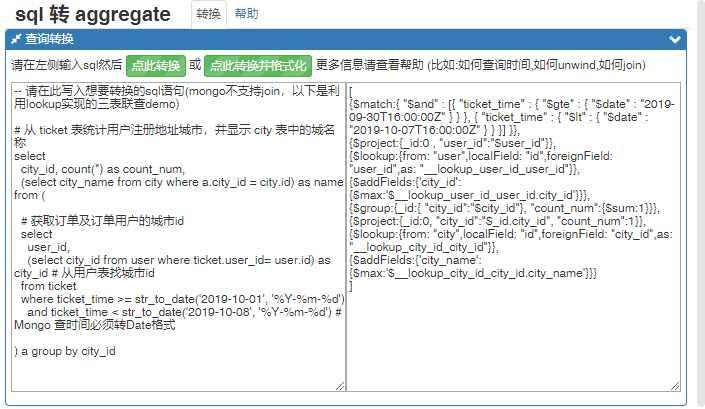
-- 从 ticket 表统计收货地址城市,并显示 city 表中的城名称 select city_id, count(*) as count_num, (select city_name from city where table_a.city_id = city.id) as name from ticket group by city_id-
输出 Aggregate:
[ {"$group":{"_id":{"city_id":"$city_id"},"count_num":{"$sum":1}}}, {"$project":{"_id":0,"city_id":"$_id.city_id","count_num":1}}, {"$lookup":{"from":"city","localField":"id","foreignField":"city_id","as":"__lookup_city_id_city_id"}}, {"$addFields":{"city_name":{"$max":"$__lookup_city_id_city_id.city_name"}}} ]如果有 group by 时 lookup 默认会放在 group by 之后执行, 如果需要在其之前执行, 可以额外嵌套一层
-- 从 ticket 表统计用户注册地址城市,并显示 city 表中的城名称 select city_id, count(*) as count_num, (select city_name from city where b.city_id = city.id) as name from ( -- 获取订单及订单用户的城市id select user_id, (select city_id from user where ticket.user_id= user.id) as city_id # 从用户表找城市id from ticket where ticket_time >= str_to_date('2019-10-01', '%Y-%m-%d') and ticket_time < str_to_date('2019-10-08', '%Y-%m-%d') # Mongo 查时间必须转Date格式 ) b group by city_id注意事项
-
mongo 只能支持 select 和 from 子查询, 无法支持 where 子查查询 和 join
-
此工具类暂时不支持加减乘除运算
-
mongo对数据类型敏感。
MySQL 中的 date > str_to_date(‘2019-04-07’, ‘%Y-%m-%d’) 可以写为 date > ‘2019-04-07’。
但 mongo 不可以。 mongo 中 必须写成 date > str_to_date(‘2019-04-07’, ‘%Y-%m-%d’) 或 date > toDate(‘2019-04-07’)
web 版
- 以下是web版效果图 在线测试
- 手机扫码试用
相关页面
