简介
在 mysql, hive, presto 等架构中都有自定义 udf 函数的功能.
本工具包同样也提供类似能力.
常见的自定义函数分为三种: UDF(一进一出) UDAF(多进一出) UDTF(一进多出)
本工具包目前支持自定义 UDF 和 UDAF 函数, 并且内置 unwind 这个 UDTF 函数.
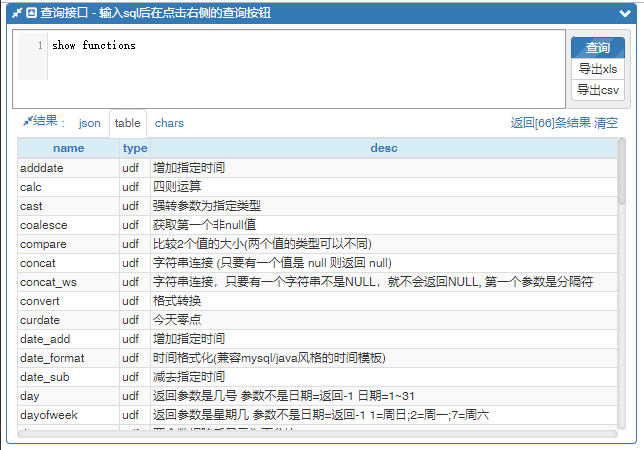
查询当前可用的函数
show functions
函数名不区分大小写
自定义 UDF
- 以下是注册自定义 UDF 函数的代码
import cn.sybn.util.conver.udf.SybnUdfPool;
import cn.sybn.util.stat.udaf.base.BaseCountUdaf;
SybnUdfPool.register(CalcUdf.getInstance());
- 以下是 upper 函数的定义代码.
// upper("aAa") => "AAA"
public class SqlUpperUdf implements SybnUdf.SybnSingleArgUdf<String> {
private static SqlUpperUdf instance = new SqlUpperUdf();
private SqlUpperUdf() {
}
public static SqlUpperUdf getInstance() {
return instance;
}
@Override
public String getName() {
return "upper";
}
/**
* 当前函数有多个名字
*/
@Override
public List<String> getNames() {
return ListUtil.toList("toUpperCase", "upper");
}
@Override
public String getDesc() {
return "返回参数转字符串后的大写格式";
}
@Override
public String getRes(Object value) {
if (value == null) {
return "";
}
return value.toString().toUpperCase();
}
}
非流式计算的自定义 UDAF
非流式计算时, udf 引擎不负责处理 group by, 只处理 group by 分组后的 subList. 所有的 udf 函数共享一次 group by 分组操作.
非流式计算时, 无法多线程计算, 自然也无法在执行半途中获取中间结果.
- 以下是注册自定义 UDAF 函数的代码
import cn.sybn.util.conver.udf.SybnUdfPool;
import cn.sybn.util.conver.udf.singlearg.CalcUdf;
StatUdafPool.register(BaseCountUdaf.getInstance());
- 以下是 upper 函数的定义代码.
public class BaseCountUdaf implements BaseUdaf {
private static BaseCountUdaf instance = new BaseCountUdaf();
private BaseCountUdaf() {
}
public static BaseCountUdaf getInstance() {
return instance;
}
@Override
public String getUdafName() {
return "count";
}
@Override
public <T> void udaf(@NonNull UdafConf udaf, @NonNull String udafKey, List<T> subList, Map<String, Object> newMap, Object defaults) {
String aggKey = udaf.getArg(0, udafKey);
int agg = DatasMatchUdfUtil.count(subList, aggKey);
// 将新数据存数在udafKey中
newMap.put(udafKey, agg);
}
}
流式计算的自定义 UDAF
流式计算时需要考虑多线程结果集合并, 因此会出现 merge 函数合并不同线程的结果集. 相关设计参考了 spark 的 udaf 引擎.
流式计算引擎可以允许在 stram 流未结束时, 查询中间计算结果.
- 以下是注册自定义 UDAF 函数的代码
import cn.sybn.util.java8.stat.udaf.StreamUdafPool;
StreamUdafPool.register(udaf);
- 以下是 upper 函数的定义代码.
SybnStreamUdaf udaf = new AbsMyGroupUdaf() {
private static final long serialVersionUID = 1L;
AtomicLong agg = new AtomicLong(0);
@Override
public String getUdafName() {
return "count";
}
@Override
public void put(Object value) {
if (value != null) {
agg.addAndGet(1);
}
}
@Override
public void merge(MyGroupUdaf myGroupUdaf) {
Integer intermedia = (Integer) myGroupUdaf.getIntermedia();
agg.addAndGet(intermedia);
}
@Override
public Object getIntermedia() {
return agg.get();
}
@Override
public Object get() {
return agg.get();
}
};
